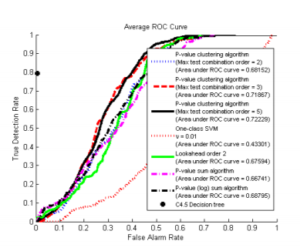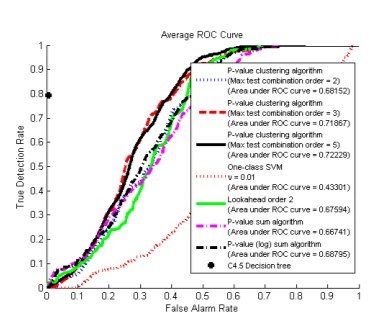
We focus on detecting samples from anomalous latent classes, “buried” within a collected batch of known (“normal”) class samples. In our setting, the number of features for each sample is high. We posit and observe to be true that careful “feature selection” within unsupervised anomaly detection may be needed to achieve the most accurate results. Our approach effectively selects features (tests), even though there are no labeled anomalous examples available to form a basis for standard (supervised) feature selection. We form pairwise feature tests based on bivariate Gaussian mixture null models, with one test for every pair of features. The mixtures are estimated using known class samples (null “training set”). Then, we obtain p-values on the test batch samples under the null hypothesis. Subsequently, we calculate approximate joint p-values for candidate anomalous clusters, defined by (sample subset, test subset) pairs. Our approach sequentially detects the most significant clusters of samples in a networking context. We compare our “p-value clustering algorithm”, using ROC curves, with alternative p-value based methods and with the one-class SVM. All the competing methods make sample-wise detections, i.e. they do not jointly detect anomalous clusters. The anomalous class was either an HTTP bot (Zeus) or peer-to-peer (P2P) traffic. Our p-value clustering approach gives promising results for detecting the Zeus bot and P2P traffic amongst Web.
The paper link:
ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=6814181