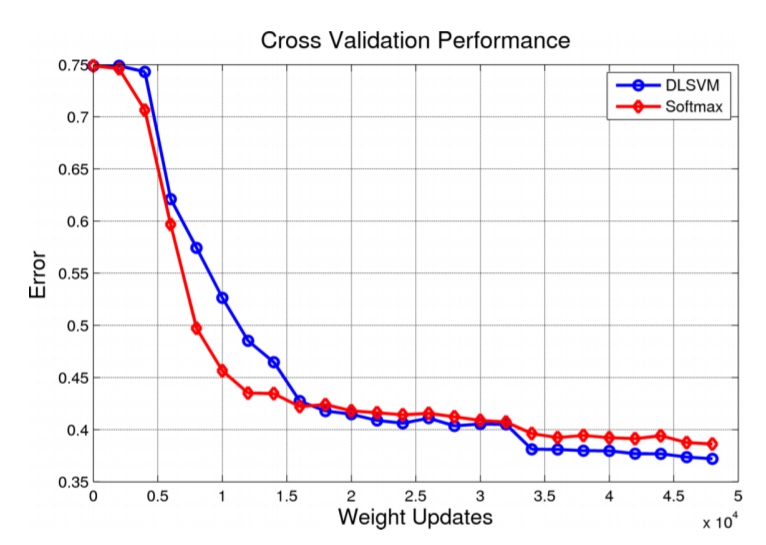
In this paper, they [have demonstrated] a small but consistent advantage of replacing the softmax layer with a linear support vector machine [in fully-connected and convolutional neural networks]. Learning minimizes a margin-based loss instead of the cross-entropy loss. While there have been various combinations of neural nets and SVMs in prior art, [their] results using L2-SVMs show that by simply replacing softmax with linear SVMs gives significant gains on popular deep learning datasets MNIST, CIFAR-10, and the ICML 2013 Representation Learning Workshop’s face expression recognition challenge.
The link of the paepr: arxiv.org/pdf/1306.0239.pdf
For nay question, please let me know 🙂